삽입 정렬(Insertion Sort)
리스트가 정렬된 부분과 정렬 안된 부분으로 나뉜다. 정렬 안된 부분의 가장 왼쪽 원소를 정렬된 부분의 적절한 위치에 '삽입'하는 방식의 알고리즘이다.
선택 정렬에 비해 구현 난이도가 높지만, 일반적으로 더 효율적으로 동작한다.
동작 방법
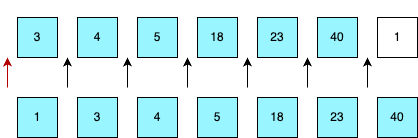
숫자 4, 3, 40, 5, 23, 18, 1 이 순서대로 준비되어 있다.

1) 첫 번째 원소 '4'는 정렬되어 있다고 판단하고, 두 번째 원소인 '3'이 어떤 위치로 들어갈지 판단한다.
화살표가 들어갈 수 있는 위치이고 빨간색 화살표가 들어가야하는 위치이다.

2) 이어서 '40'이 어떤 위치로 들어갈 지 판단한다. 원래 자리가 '40'이 들어갈 자리이다.

3) 이어서 '5'가 어떤 위치로 들어갈 지 판단한다.

4) 마지막으로 '1'이 어떤 위치로 들어갈 지 판단하고 정렬하면 오름차순으로 정렬된다.
실습
동작 방법에서 살펴본대로 삽입 정렬이 작동하는지 실습을 통해 확인해보자.
## 리스트에 데이터 준비
array = [4, 3, 40, 5, 23, 18, 1]파이썬 리스트에 데이터를 준비했다.
for i in range(1, len(array)):
for j in range(i, 0, -1): ## 인덱스 i부터 1까지 1씩 감소
if array[j] < array[j - 1]: ## 한 칸씩 왼쪽으로 이동
array[j], array[j - 1] = array[j - 1], array[j]
else: ## 자기보다 작은 원소값을 만나면 멈춤
break맨 앞에 있는 원소는 정렬되어 있다고 가정했으므로 1번째 인덱스부터 탐색한다.
리스트의 뒤에서부터 원소 값을 비교하며 삽입 정렬을 수행한다.
print(array)
## 출력값
[1, 3, 4, 5, 18, 23, 40]삽입 정렬 후 리스트가 오름차순으로 정렬되어 있는 것을 알 수 있다.
수행 시간
삽입 정렬은 리스트가 거의 정렬되어 있을 때 수행 시간이 매우 빠르고, 반대로 정렬되어 있을 경우 매우 느리다는 특징이 있다. 이를 보아 삽입 정렬은 민감한 알고리즘임을 알 수 있다. 삽입 정렬의 시간 복잡도는 아래와 같다.
1. 이미 정렬되어 경우 $$ N-1$$
2. 반대로 정렬되어 있는 경우 $$ (N-1) + (N-2) + \cdots + 2 + 1 = {N(N-1) \over 2} = O(N^2) $$
정리
1. 삽입 정렬은 정렬 되지 않은 원소를 하나 골라 적절한 위치에 '삽입'한다.
2. 삽입 정렬은 정렬 되어 있는 데이터일수록 빠른 시간 복잡도를 가진다.
'알고리즘' 카테고리의 다른 글
| [알고리즘] 퀵 정렬 (0) | 2022.11.04 |
|---|---|
| [알고리즘] 계수 정렬 (0) | 2022.11.04 |
| [알고리즘]선택 정렬 (0) | 2022.09.14 |
| [자료구조]큐 (0) | 2022.09.13 |
| [자료구조]스택 (0) | 2022.09.13 |